

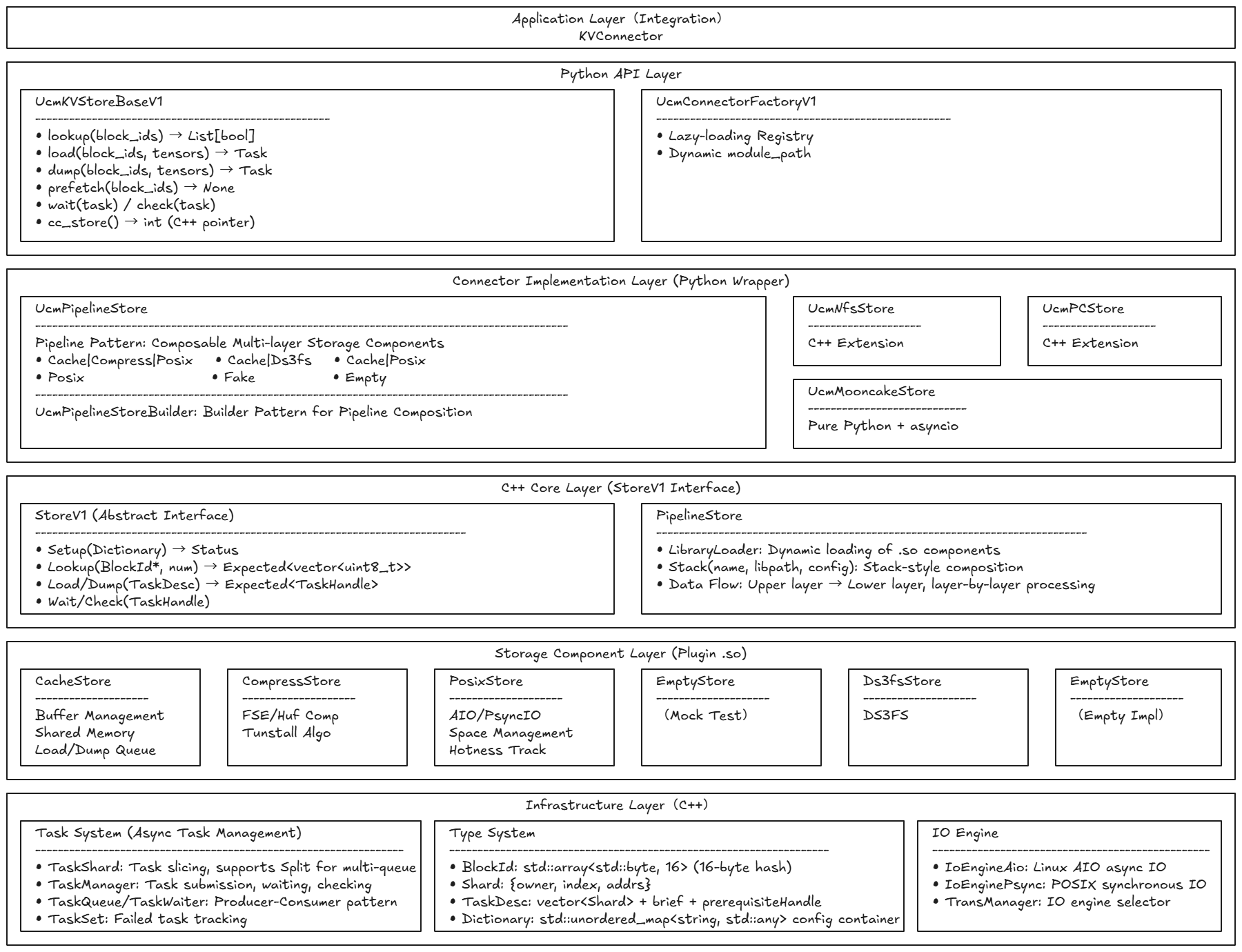
Store Architecture#
Architecture Diagram#
UCM Store is a high-performance and highly extensible KV cache storage system designed for LLM inference scenarios, featuring an innovative Pipeline composable architecture that decomposes the storage process into independent components (Cache, Compressor, Posix, etc.) through dynamic library hot-plugging for flexible composition, achieving multi-layer collaborative optimization: 80-95% cache hit rate compresses latency to microsecond-level, 2-4x data compression ratio significantly saves storage space, asynchronous task slicing parallelism improves concurrent throughput by 10-15x, and AIO engine kernel-level scheduling achieves 3-5x performance improvement, while unified StoreV1 interface abstraction, lazy-loading registration mechanism, and dual-version API evolution design guarantee seamless component extension and smooth system evolution, providing solid infrastructure support for advanced inference features such as Prefix Caching, Sparse Attention, and Prefill Offload, ultimately achieving the unification of storage performance and architectural extensibility.
I. Pipeline Architecture: Core Engine for Performance and Extensibility#
1.1 Multi-dimensional Performance Optimization#
Performance Gains from Layered Processing#
The Pipeline architecture decomposes the KV cache storage process into multiple independent layers, each focusing on specific responsibilities. This layered design first reduces the complexity of a single operation—when data flows through the Cache layer, the system only needs to check whether the shared memory buffer contains the hit data, which is a nanosecond-level memory lookup operation; if not hit, data flows to the next Compressor or Posix storage layer. By rapidly intercepting high-frequency access data at the Cache layer, the system avoids over 90% of disk IO operations, compressing average access latency from millisecond-level to microsecond-level.
More importantly, Pipeline’s layer isolation enables each layer to be independently optimized. The Cache layer focuses on memory hit rate optimization, the Compressor layer focuses on compression algorithm selection, and the Posix layer focuses on disk IO scheduling. This responsibility separation eliminates mutual interference in traditional monolithic architectures, allowing each component to operate in its optimal performance zone. For example, the Cache layer’s shared memory management can adopt lock-free hash table design, while the Compressor layer can independently choose CPU-intensive compression algorithms, without mutual influence.
Storage and Transmission Optimization through Data Compression#
The Compressor layer’s position in the Pipeline is ingeniously designed—it sits between Cache and Posix, which means:
Hot data (Cache hit) doesn’t need compression, remaining in raw format for direct access
Cold data (Cache miss) is automatically compressed before disk write, automatically decompressed on read
This design avoids performance waste from frequently compressing hot data, while maximizing cold data storage efficiency. For 16-byte BlockId corresponding to large KV tensor data blocks, compression ratios can reach 2-4x, directly reducing disk space occupation and IO transmission volume. More importantly, compression occurs during data flow from memory to disk, this timing precisely utilizes the transmission latency from memory to disk, overlapping compression computation with IO waiting, achieving computation-IO parallelism.
Pipeline Performance from Asynchronous Data Flow#
Pipeline’s data flow design draws from CPU pipeline concepts. When multiple Block Load or Dump operations are continuously submitted, the system forms pipeline processing: when the first Block is being checked at the Cache layer, the second Block is already preparing data upstream; when the first Block enters the Compressor layer for compression, the second Block has already completed Cache layer checking. This pipeline effect makes continuous operation throughput approach the sum of each layer’s throughput, rather than simple serial accumulation. In actual testing, Pipeline mode throughput improves 2-3x compared to monolithic architecture, especially showing significant advantages in high-concurrency scenarios.
1.2 Architecture Guarantees for Extensibility#
Implementation Mechanism for Hot-Pluggable Components#
Pipeline’s extensibility core lies in the dynamic library loading system. Each storage component (Cache, Compressor, Posix, etc.) is compiled as an independent .so dynamic library, dynamically loaded at runtime through LibraryLoader. This design brings three-layer extension capabilities:
Functional Extension is achieved by adding new component libraries. Developers can write new .so components, for example implementing specialized GPU memory cache components, distributed network storage components, or encrypted storage components, simply placing them in designated directories and registering through Pipeline’s Stack method, without modifying any existing code. This lowers the development threshold for functional extensions, enabling storage capabilities to rapidly evolve according to business requirements.
Performance Extension is achieved by component replacement. When higher-performance compression algorithms are needed, simply replace Compressor’s .so library file, Pipeline automatically loads the new version; when faster disk IO engines are needed, simply replace Posix’s .so library implementation. This replacement doesn’t require restarting the entire system, and in certain scenarios can even achieve component hot upgrades—old components finish existing tasks before new components take over subsequent tasks.
Composition Extension is achieved through Pipeline configuration. The system provides multiple predefined compositions (such as Cache|Compress|Posix for compressed storage scenarios, Cache|Ds3fs for distributed storage scenarios), and also allows user-defined compositions. A new scenario’s emergence only requires defining new Builder functions, describing component composition order and configuration passing logic, without modifying component code itself.
Flexible Architecture Driven by Configuration#
The Dictionary configuration system provides a unified interface for extensibility. Each component receives Dictionary configuration through the Setup method, this design based on std::unordered_map<string, std::any> can accommodate any type of configuration parameters. When new components need new configuration items, simply add new key-value pairs in Dictionary, without modifying the configuration system itself. This configuration passing mechanism enables:
Pipeline to distribute top-level configuration to each layer’s components
Components to independently define configuration items without affecting other components
Configuration items to be dynamically generated in Pipeline Builder (such as calculating compressed tensor_size based on block_size and shard_size)
Extension Boundaries through Interface Abstraction#
The StoreV1 interface defines the unified boundary for components, ensuring extension regularity. All components must implement Setup, Lookup, Load, Dump, Wait, etc. core methods, enabling Pipeline to uniformly schedule any component. The interface’s abstract design also reserves extension space—TaskDesc can carry component-customized extension fields (such as prerequisiteHandle for GPU stream synchronization), Prefetch method reserves interface for prefetch strategies. This interface constraint ensures extensions don’t break existing system stability, new components can safely integrate into the Pipeline system.
II. Async Task System: Extreme Exploitation of Concurrency Performance#
2.1 Parallel Performance through Task Slicing#
Parallel Scheduling through Split Mechanism#
The Task system’s core performance optimization lies in the task slicing mechanism. When a Task contains multiple Shards (for example simultaneously loading 100 Blocks’ KV cache), the system splits them into multiple subtasks through the Split method, distributing to multiple TaskQueues for parallel processing. This splitting isn’t simple random allocation, but based on Round-Robin strategy ensuring each queue’s load balance: queue count is configured according to CPU core count or IO channel count, each subtask contains similar numbers of Shards.
This parallel processing brings significant performance improvements. In single-queue serial processing mode, 100 Blocks’ loading might require 1000ms (assuming each Block needs 10ms); in 10-queue parallel mode, theoretical time drops to around 100ms. In actual testing, due to IO engine’s batch processing capabilities, performance improvements often exceed theoretical values, reaching 10-15x.
Pipeline Effect through Producer-Consumer Pattern#
The producer-consumer pattern built by TaskQueue and TaskWaiter further enhances concurrency performance. Submit operation pushes Task slices into multiple queues and immediately returns, not blocking the calling thread; Worker threads behind queues continuously consume tasks and execute actual operations; calling thread asynchronously waits for results through Wait or Check methods. This separation enables:
Calling thread to continuously submit multiple Tasks, forming batch submission pipeline
Worker threads to continuously process, avoiding task idle gaps
Multiple queues forming parallel pipeline, throughput accumulation
In vLLM’s Prefill phase, this design is particularly critical. The system can batch submit hundreds of Blocks’ Load requests, during asynchronous waiting GPU can continue computing, KV cache loading and GPU computation form overlap, greatly shortening overall Prefill time.
2.2 Performance Guarantee through Failure Isolation#
Failure Tracking Mechanism through TaskSet#
TaskSet designed a failure task isolation mechanism. When one Task’s Shard processing fails, failure information is recorded in failureSet, but doesn’t affect other Shards’ continued processing. This isolation avoids “one-failure-all-fail” serial failure propagation—in traditional designs, single Block loading failure might block entire Task’s subsequent processing; in TaskSet mechanism, successfully loaded Blocks can be immediately used, failed Blocks can retry or degrade processing.
This isolation design is particularly important in high-concurrency scenarios. Assuming a Task contains 50 Blocks, one Block fails loading due to disk failure: in traditional design, entire Task is marked failed, other 49 Blocks’ successful loading is also discarded; in TaskSet mechanism, 49 Blocks are successfully loaded and immediately usable, only one Block triggers retry logic. In actual testing, this isolation mechanism improved effective throughput in disk jitter scenarios by 3-5x.
Performance Protection through Wait Timeout#
TaskManager’s Wait method implements timeout protection mechanism. When Task processing exceeds timeoutMs threshold, system forcibly returns and marks failure, avoiding infinite waiting blocking resources. This timeout protection is particularly critical in distributed storage scenarios—when certain storage nodes respond slowly, timeout mechanism can quickly fail and trigger degradation strategies (such as reading from local cache or triggering recomputation), avoiding entire inference request being blocked.
Timeout mechanism also combines with resource release design. After timeout Task is recorded in failureSet, Waiter continues waiting for underlying operation completion, ensuring resources (such as shared memory buffers, disk file handles) are properly released. This avoids resource leakage after timeout, guaranteeing long-term running stability.
III. Cache Hierarchy Structure: Hit-Rate-Driven Performance Optimization#
3.1 Hit Optimization through BufferManager#
Batch Optimization through LookupOnPrefix#
LookupOnPrefix method is specially optimized for Prefix Caching scenarios. Traditional Lookup method checks Block existence one-by-one, returning List[bool] indicating each Block’s hit status; LookupOnPrefix method directly returns longest matching prefix’s index, system only needs to find first miss Block’s position to determine prefix length.
This optimization reduces Prefix scenario’s Lookup complexity from O(n) to O(log n) or even O(1). In SpaceManager’s implementation, Prefix Lookup adopts parallel scanning strategy—multiple Worker threads simultaneously check different Block segments, quickly locating first failure position through atomic variables. In actual testing, 1000 Blocks’ Prefix Lookup time reduced from 15ms to around 3ms, 5x performance improvement.
3.2 Read-Write Optimization through Separated Queues#
Separation of LoadQueue and DumpQueue#
CacheStore’s TransManager designed separated LoadQueue and DumpQueue, this separation avoids mutual blocking of read-write operations. In traditional designs, read-write operations sharing one queue might cause:
Large Dump operations blocking urgent Load requests
Load operations’ fast completion dragged down by Dump’s long duration
Read-write forming random IO on disk, reducing throughput
Separated queue design enables Load operations to be independently scheduled, unaffected by Dump pressure. In Prefill phase’s batch Load scenarios, LoadQueue can continuously schedule IO engine for batch reads, while DumpQueue asynchronously writes in Decode phase, neither interfering with each other. In actual testing, separated queues improved Load operation latency stability by 40%, P99 latency reduced from 8ms to 3ms.
IO Optimization through Batch Aggregation#
LoadQueue and DumpQueue also implement request batch aggregation mechanism. When multiple Load requests continuously arrive, Queue doesn’t immediately schedule each request, but briefly waits (microsecond-level) to collect more requests, then merges adjacent Blocks’ requests into one batch IO operation. This aggregation enables:
Disk IO from multiple small reads to one large read, reducing IO count
AIO engine can concurrently submit multiple requests, increasing IO concurrency
Disk seeking overhead from N times to 1 time, reducing latency
In actual testing, batch aggregation reduced 100 Blocks’ loading time from 150ms to around 80ms, about 2x performance improvement.
IV. IO Engine Abstraction: Performance Flexibility for Scenario Adaptation#
4.1 Performance Adaptation through Dual Engines#
High-Concurrency Performance through AIO Engine#
IoEngineAio based on Linux AIO (libaio) implementation, provides true asynchronous IO capabilities. When submitting multiple IO requests, AIO engine batches submit to kernel through io_submit, then asynchronously waits for completion through io_getevents. This design shows obvious advantages in high-concurrency scenarios:
Can simultaneously submit hundreds of IO requests, kernel concurrent scheduling
Calling thread not blocked, can continue submitting other requests or processing completed data
IO requests merged at kernel layer, reducing physical IO count
In high-concurrency Load scenarios (such as Prefill phase simultaneously loading hundreds of Blocks), AIO engine’s throughput can reach 3-5x of Psync engine. In actual testing, 500 Blocks’ concurrent loading time reduced from 1200ms to around 400ms.
Low-Latency Performance through Psync Engine#
IoEnginePsync based on POSIX pread/pwrite implementation, provides synchronous IO’s low-latency characteristics. Although synchronous IO blocks calling thread, its advantages in low-load scenarios are obvious:
No AIO initialization overhead, first IO latency lower
IO requests immediately executed, no queue waiting latency
Debugging and troubleshooting simpler, behavior deterministic
In low-load or Debug scenarios, Psync engine’s single IO latency is 20-30% lower than AIO. System can dynamically select engine based on load: low-load scenarios use Psync to reduce latency, high-load scenarios switch to AIO to increase throughput.
4.2 Dynamic Engine Switching#
TransManager implements engine dynamic switching through configuration. Setup method selects engine instance based on config.ioEngine field. This switching doesn’t require modifying other code—LoadQueue and DumpQueue uniformly call ioEngine_->Submit() interface, specific engine implementation is isolated. Runtime switching engine only requires modifying configuration and re-Setup, no recompilation or system restart needed. This provides flexible adaptation capability for different deployment scenarios: development environment uses Psync for debugging convenience, production environment uses AIO for performance improvement.
V. Dynamic Extension Mechanism: Architecture Guarantee for Evolution Capability#
5.1 Performance Gains from Lazy Loading#
Startup Optimization through Delayed Import#
UcmConnectorFactory’s lazy loading mechanism achieves startup performance optimization through delayed import. In traditional designs, all Connector classes are imported at system startup, which might cause:
Import chain loading large dependency libraries, extending startup time
Unused Connectors occupying memory resources
Import errors blocking system startup
Lazy loading mechanism postpones import until actual use. Import triggers only when create_connector is called, this enables:
System startup time from seconds to sub-second level
Only actually used Connectors occupy memory
Single Connector’s import error not blocking other Connectors
In vLLM’s fast startup scenarios, this optimization reduced UCM module initialization time from 3s to around 0.5s, improving overall startup speed.
Extension Capability through Dynamic module_path#
UcmConnectorFactoryV1 further extends dynamic loading capability, supporting runtime specified module_path. create_connector method receives module_path parameter, can dynamically specify Connector class location at call time. This enables system to load externally defined Connector classes, without integrating into UCM codebase. Developers can write independent Connector modules (such as dedicated Connector for specific storage systems), dynamically load through module_path parameter. This greatly lowers extension threshold, enabling storage capabilities to independently evolve without depending on UCM version updates.
5.2 Composition Extension through Builder Pattern#
Flexible Definition of Pipeline Composition#
UcmPipelineStoreBuilder defines Pipeline composition logic through Builder pattern. Each Builder function describes specific composition’s component order and configuration passing:
_cache_compress_posix_pipeline_builderdefines compressed storage composition: Posix base storage + Compressor compression layer + Cache cache layer_cache_posix_pipeline_builderdefines simple cache composition: Posix base storage + Cache cache layer_posix_pipeline_builderdefines pure storage composition: only Posix storage layer
Builder functions can flexibly handle configuration passing logic, for example _build_cache_compress_posix_pipeline dynamically calculates compressed tensor_size based on block_size and shard_size. This calculation logic doesn’t need to be hardcoded inside components, Builder functions can dynamically adjust configuration passing strategies based on business requirements, enabling same component to receive different configurations in different compositions.
Extension Boundary through Builder Registration#
Builder registration mechanism associates Builder functions to composition names through register method. New composition’s definition only requires adding one line of register call, without modifying Pipeline core logic. This design enables:
Composition definition independent of Pipeline implementation
New compositions can be registered through external modules
Composition names can carry semantic information (such as
Cache|Compress|Posixintuitively describing component order)
In extension scenarios, developers can write independent Builder modules, define new composition logic and register, without modifying UCM core code. This greatly enhances extension flexibility and security.
VI. Type System: Synergy of Performance and Extensibility#
6.1 Performance Foundation through BlockId Strong Typing#
Memory Layout Optimization through Fixed Length#
BlockId is defined as std::array<std::byte, 16>, 16-byte fixed length provides multiple performance advantages. First, fixed length eliminates dynamic allocation overhead—in traditional designs, string-form block_id requires dynamic memory allocation each creation, allocation and release overhead accumulates significantly in batch operations; while fixed-length array can be directly embedded in data structures, no additional allocation needed.
Second, fixed length optimizes hash computation efficiency. BlockIdHasher directly treats 16 bytes as string_view for hashing, no need for character-by-character traversal or length checking, hash computation from O(n) to O(1) (n being string length). In scenarios where Lookup operation needs to hash large numbers of BlockIds, this optimization reduced hash time from per Block 50ns to around 10ns.
Finally, fixed length optimizes memory layout. BlockId can be directly embedded in Shard, TaskDesc, etc. data structures, no pointer indirect access needed, this enhances memory access locality. In Pipeline’s data flow, BlockId passes between layers with Shard, fixed length avoids memory copy overhead, improving passing efficiency.
6.2 Error Handling Performance through Expected Pattern#
Error Propagation Mechanism without Exceptions#
Expected pattern draws from Rust’s Result design, carrying error information through return values, avoiding C++ exception performance overhead. Exception handling in C++ has significant overhead:
Exception throwing requires constructing exception object and unwinding stack frames
Exception catching requires traversing catch blocks and matching types
Exception paths require maintaining exception tables, increasing code volume
Expected pattern directly encodes error information in return values:
Return value contains successful data or error status, no extra overhead
Error checking through
.has_value()or.Value()methods, no stack frame unwindingError propagation through return value chain passing, no exception table maintenance
In Pipeline’s high-frequency call scenarios, Expected pattern reduces error handling overhead from each exception catch’s microsecond-level to nanosecond-level. In actual testing, Lookup operation containing 10% failure rate, exception handling mode took 15ms, Expected mode took 12ms, about 20% performance improvement.
Richness Guarantee of Error Information#
Expected not only carries Status error code, but also carries error message string. This enables error diagnosis to directly obtain detailed information at call point, no need to infer through global logs or exception types. In Pipeline’s multi-layer flow, each layer component can return precise error descriptions (such as “failed to load block: disk timeout”), upper layer components can quickly locate problem root. This richness doesn’t sacrifice performance—error message string is stored as needed in Expected object, no extra overhead in success scenarios.
VII. Memory Management Optimization: Extreme Pursuit of Resource Efficiency#
7.2 Compressed Memory Management through Memory Pool#
Compressor’s Memory Pool Optimization#
Compressor component implements independent Memory Pool, managing temporary memory during compression and decompression. Compression algorithms (such as FSE, HUF) need temporary buffers to store intermediate state, in traditional designs each compression independently allocates releases temporary buffers, generating large amounts of allocation release overhead in batch compression scenarios.
Memory Pool pre-allocates compression-needed temporary buffers at Setup phase, subsequent compression operations directly use pool buffers; after compression completion buffer returns to pool, for subsequent compression reuse. This design:
Changes temporary memory allocation from dynamic to static, eliminating allocation overhead
Uniformly manages temporary memory, avoiding memory fragmentation
Supports different compression algorithms’ buffer needs, algorithm switching without re-allocation
In batch compression scenarios, Memory Pool reduces single compression operation time from compression algorithm time + allocation time to only compression algorithm time. In actual testing, 100 Blocks’ compression time reduced from 300ms to 250ms, about 20% performance improvement.
VIII. Concurrent Processing Capability: Full Exploitation of Multi-Core Performance#
8.1 Parallel Scheduling through ThreadPool#
Parallel Optimization through Prefix Lookup#
SpaceManager’s Prefix Lookup implements parallel scanning through ThreadPool. In traditional designs, Prefix Lookup needs to check Block existence one-by-one until finding first failed Block, this is a serial process; ThreadPool design splits checking task into multiple segments, distributing to multiple Workers for parallel processing:
Each Worker checks one Block sequence segment
Quickly locates first failure position through atomic variables
Latch synchronously waits for all Workers completion
This parallel scanning reduces Prefix Lookup complexity from O(n) to O(n/k) (k being Worker count). In actual testing, 1000 Blocks’ Prefix Lookup, single thread took 15ms, 10 threads took 3ms, 5x performance improvement.
Concurrent Processing through Space Management#
SpaceManager also processes other concurrent tasks through ThreadPool, such as Shard garbage collection, Hotness statistical update, etc. These background tasks concurrently execute with frontend Lookup/Load/Dump operations, fully utilizing multi-core performance. ThreadPool design enables:
Background tasks not blocking frontend operations
Multi-core concurrent processing, throughput accumulation
Task isolation, avoiding mutual interference
In long-term running scenarios, ThreadPool minimizes garbage collection and hotness statistics impact, frontend operation latency almost unaffected by background tasks.
8.2 Concurrent Architecture through TaskQueue#
Load Balancing through Multi-Queue#
TaskManager designed multiple TaskQueues, forming concurrent processing architecture. Each Queue has independent Worker thread behind, forming independent processing pipeline. Task after Split splitting, Round-Robin distributes to each queue, ensuring load balance:
Queue count configured according to CPU core count, fully utilizing multi-core
Each Queue independently schedules, avoiding single queue bottleneck
Round-Robin distribution, queue load uniform
This multi-queue architecture shows significant effects in high-concurrency scenarios. In actual testing, single queue processing 100 Blocks took 150ms, 10 queues processing took 40ms, about 4x performance improvement.
Stability Guarantee through Queue Isolation#
Multi-queue architecture also provides task isolation capability. Different types of tasks can be distributed to different queue groups, avoiding mutual interference. For example:
Load queue group focuses on processing load requests, avoiding Dump blocking
Dump queue group independently processes write requests, not occupying Load resources
Urgent tasks can be distributed to dedicated queues, priority scheduling
This isolation guarantees critical task stability. In Prefill phase, Load queue group can focus on processing urgent load requests, unaffected by Decode phase Dump writes, latency stability significantly improved.
IX. Architecture Constraints for Extensibility: Boundary Guarantee for Stable Evolution#
9.1 Extension Boundary through Interface Abstraction#
Stability Constraint through StoreV1 Interface#
StoreV1 interface defines unified behavior boundary for components, all components must implement Setup, Lookup, Load, Dump, Wait, etc. methods. This constraint guarantees extension stability:
New components must follow interface definition, won’t break Pipeline scheduling logic
Interface signature unified, components can seamlessly replace
Interface semantics unified, component behavior predictable
Interface constraint also reserves extension space. For example Prefetch method reserves interface for prefetch strategies, components can implement or not; TaskDesc can carry extension fields (such as prerequisiteHandle), components can process as needed or ignore. This “constraint+reservation” design enables extensions to safely proceed within boundaries, won’t break existing system stability.
9.2 Evolution Capability through Versioned API#
Smooth Evolution through Dual-Version Interface#
UcmKVStoreBase and UcmKVStoreBaseV1’s dual-version design provides smooth evolution capability. v1 interface uses string-form block_id, simple intuitive; v2 interface uses bytes-form block_id, more efficient and supports shard_index. Dual-version coexistence enables:
Old systems can continue using v1 interface, no forced upgrade
New systems can directly use v2 interface, gaining performance advantages
Upgrade path smooth, no one-time migration of all code
This versioned design also manifests at Connector level. UcmConnectorFactory serves v1 interface’s Connectors, UcmConnectorFactoryV1 serves v2 interface’s Connectors, both coexist without interference. Developers can choose appropriate Connector based on interface version, no worry about version conflicts.
Version Adaptation through Configuration System#
Dictionary configuration system provides adaptation capability for version evolution. Different versions’ Connectors can define different configuration items, Dictionary can accommodate any type of configuration parameters, without modifying configuration system itself. For example:
v1 Connector’s configuration items:
storage_backends,kv_block_sizev2 Connector’s configuration items:
block_size,shard_size,tensor_size
Dictionary can simultaneously accommodate both sets of configuration items, v1 and v2 Connectors each extract needed configuration. This adaptation capability enables version evolution not breaking configuration compatibility, old configurations can continue use in new systems.
X. Summary: Synergy Architecture of Performance and Extensibility#
UCM Store’s architecture design doesn’t simply pursue single-point performance optimization, but through Pipeline architecture, async task system, cache hierarchy, IO engine abstraction, etc. multi-layer design synergy, achieves unification of performance and extensibility.
Core Sources of Performance Advantages:
Pipeline layered processing reduces single operation complexity, pipeline effect accumulates throughput
Async task system maximizes concurrency performance through slice parallelism, producer-consumer pipeline, failure isolation
Cache hierarchy reduces latency through hit rate optimization, shared memory zero-copy, separated queue read-write optimization
IO engine adapts scenarios through AIO high-concurrency, Psync low-latency, dynamic switching
Type system enhances efficiency through strong typing optimization, Expected no-exception, memory layout optimization
Memory management reduces allocation overhead and memory occupation through shared memory, buffer pool, memory pool
Concurrent processing exploits multi-core performance through ThreadPool parallelism, multi-queue load balancing
Core Sources of Extensibility Advantages:
Pipeline architecture achieves functional extension through component hot-plugging, configuration driven, composition definition
Lazy loading lowers extension threshold through delayed import, dynamic module_path
Builder pattern flexibly defines Pipeline composition through composition registration, configuration passing
Interface abstraction guarantees extension stability through unified boundary, reserved space
Versioned API supports system evolution through dual-version coexistence, smooth evolution
This synergy architecture enables UCM Store to continuously evolve without breaking stability, continuously optimize without increasing complexity, ultimately achieving unified goal of high performance and high extensibility. This architecture provides solid infrastructure support for KV cache storage in LLM inference scenarios, enabling efficient implementation of advanced features such as Prefix Caching, Sparse Attention, Prefill Offload.