

GSA: Hash-Aware Top-k Attention for Scalable Large Model Inference#
🚀 Hash-Aware Sparse Attention Algorithm | 📄 ACL 2025 Paper | ⚡ NPU/GPU Hardware-Efficient
![]()
![]()
🌟 What is GSA (HATA)?#
GSA (Geometry Sparse Attention) is a groundbreaking sparse attention algorithm that revolutionizes large language model inference through Hash-Aware Top-k Attention. Published at ACL 2025, our method achieves unprecedented efficiency by intelligently selecting the most relevant kv cache blocks using trainable hash-based similarity computation.
🎯 Key Innovations#
🔍 Hash-Aware Similarity: Uses trainable hash functions to compute attention relevance, which is significantly faster than exact attention score $QK$ computation
⚡ Hardware-Efficient: Optimized for both CUDA and NPU architectures with specialized kernels
🎛️ Adaptive Sparsity: Layer-wise sparsity ratios that adapt to model characteristics
🔄 Dynamic Retrieval: Real-time query-aware block selection based on query-key similarity
💾 Memory-Efficient: Dramatically reduces KV cache HBM peak usage by leveraing UCM’s offloading capability
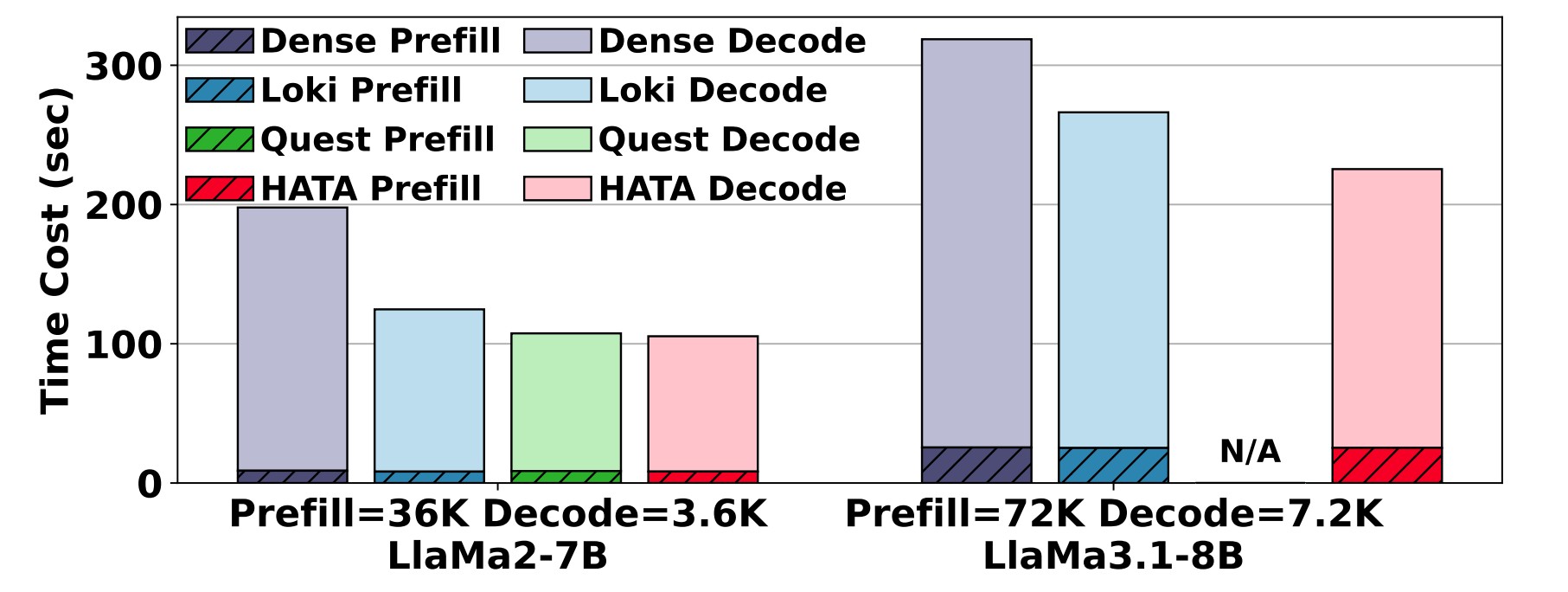
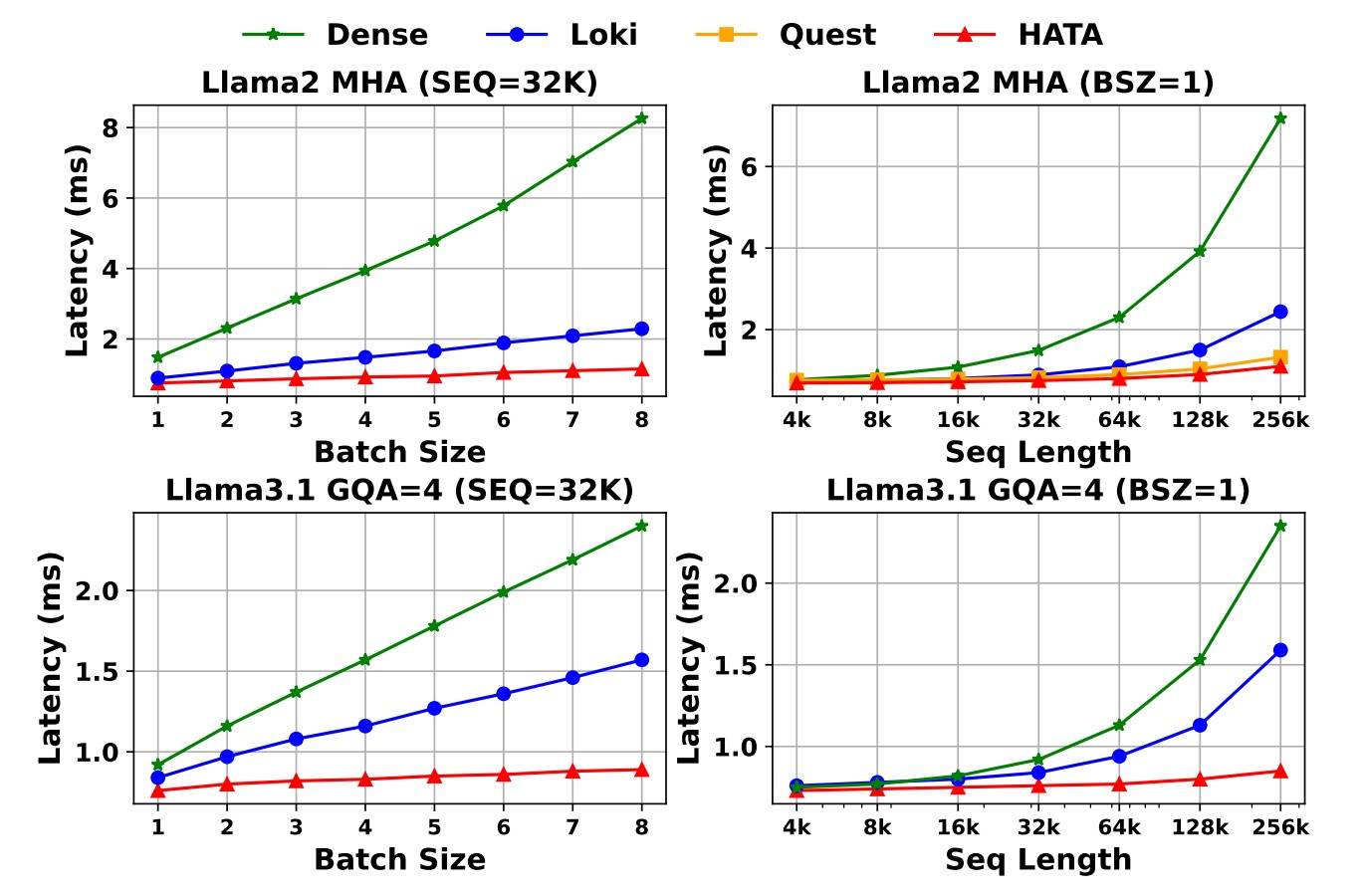
🔥 Key Results#
3-5x speedup in attention computation for long sequences
Minimal accuracy loss (< 2%) on downstream tasks
Scalable to 128K+ context lengths with linear complexity
🏆 Performance Highlights#
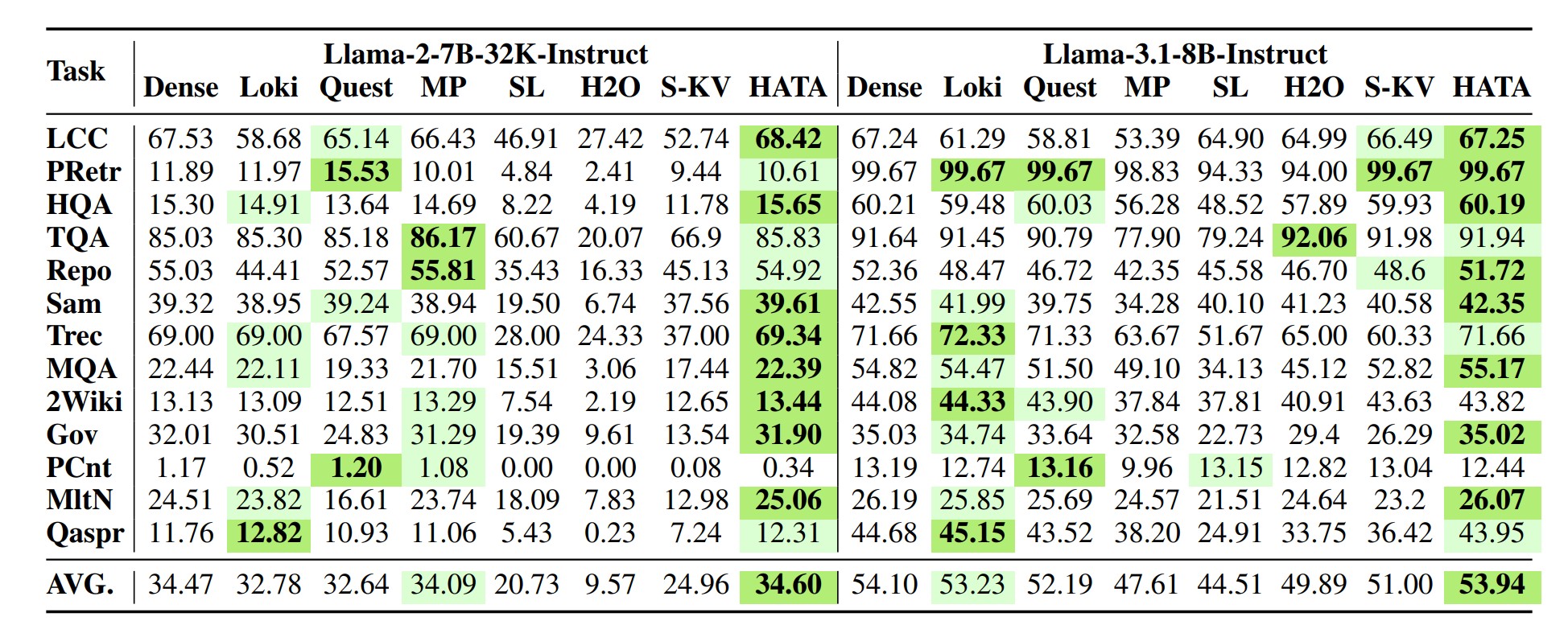
📈 Accuracy Benchmarks#
LongBench Evaluation#
🧠 How It Works#
Core Algorithm#
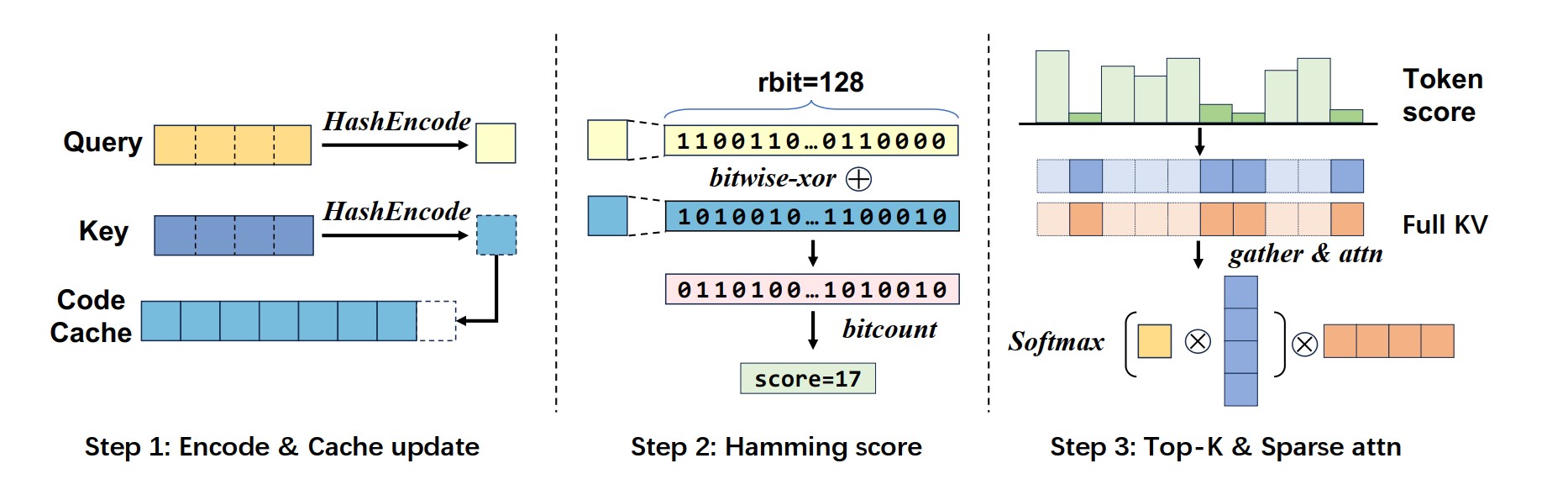
GSA operates through a sophisticated three-stage process:
🔐 Hash Encoding: Convert attention keys and queries into compact hash codes
🎯 Similarity Computation: Use efficient hash-based similarity to identify relevant blocks
📦 Selective Loading: Load only the top-k most relevant KV blocks for attention
# Simplified algorithm flow
def gsa_attention(query, key_cache, top_k_ratio):
# 1. Hash encoding
hash_query = hash_encoder.compute_hash(query)
hash_keys = hash_encoder.compute_hash(key_cache)
# 2. Similarity computation
scores = hamming_score(hash_query, hash_keys)
# 3. Top-k selection
topk_blocks = torch.topk(scores, int(len(key_cache) * top_k_ratio))
# 4. Selective attention
return attention(query, key_cache[topk_blocks], value_cache[topk_blocks])
🏗️ Architecture#
The algorithm maintains three critical windows:
Initial Window: First few blocks (always loaded)
Sparse Window: Top-k selected blocks (dynamically chosen)
Local Window: Recent blocks (always loaded)
This design ensures both efficiency and accuracy by preserving essential context while sparsifying the middle range.
🚀 Quick Start#
Offline Inference#
GSA is part of the UCM Sparse Attention module. For installation instructions, please refer to the UCM’s top-level README. Once UCM is installed, GSA is naturally supported by running the following example python scripts.
export ENABLE_UCM_PATCH=TRUE
python examples/offline_inference_gsaondevice.py
Online Inference#
export VLLM_USE_V1=1
export ENABLE_SPARSE=TRUE
export ENABLE_UCM_PATCH=1
export VLLM_HASH_ATTENTION=1
export PYTHONHASHSEED=123456
vllm serve <path_to_Qwen3-32B> \
--served-model-name Qwen3-32B \
--tensor-parallel-size 8 \
--gpu_memory_utilization 0.85 \
--block_size 128 \
--distributed-executor-backend mp \
--trust-remote-code \
--port 8234 \
--no-enable-prefix-caching \
--compilation-config \
'{
"cudagraph_mode": "PIECEWISE"
}' \
--kv-transfer-config \
'{
"kv_connector": "UCMConnector",
"kv_role": "kv_both",
"kv_connector_module_path": "ucm.integration.vllm.ucm_connector",
"kv_connector_extra_config": {
"ucm_connectors": [
{
"ucm_connector_name": "UcmPipelineStore",
"ucm_connector_config": {
"store_pipeline": "Empty",
"share_buffer_enable": true
}
}
],
"ucm_sparse_config": {"GSAOnDevice": {}}
}
}' > Qwen3-32B_TP8_GSAonDevice.log 2>&1 &
Configuration#
GSA needs a json configuration file. We have already included several configs in configs folder, including Deepseek-R1-AWQ, Deepseek-v2-lite, Qwen3-4B, Qwen3-32B, Qwen3-Coder-30B-A3B and QwQ-32B.
{
"model_name": "Qwen/Qwen3-4B",
"is_mla": false,
"hash_weight_type": "random",
"num_hidden_layers": 36,
"gpu_seq_len_threshold": 2048,
"gpu_concurrency_threshold": 4,
"npu_seq_len_threshold": 2048,
"npu_concurrency_threshold": 4,
"chunk_size": 128,
"chunk_repre_method": "max",
"head_dim": 128,
"hash_bits": 128,
"top_k_ratio_per_layer": [1, 1, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 1, 1, 1],
"top_k_index_reuse": [-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1],
"must_select_blocks": [0, -2, -1],
"hash_weight": null,
"kv_lora_rank": null,
"qk_rope_head_dim": null,
"hash_bits_kv_lora": null,
"hash_bits_qk_rope": null,
"hash_weight_kv_lora": null,
"hash_weight_qk_rope": null
}
📊 Supported Models#
Model |
Size |
Hash Bits |
Top-k Ratio |
Performance Gain |
|---|---|---|---|---|
Qwen3-4B |
4B |
128 |
0.3 |
xx |
Qwen3-32B |
32B |
128 |
0.3 |
xx |
QwQ-32B |
32B |
128 |
0.3 |
xx |
DeepSeek-R1 |
671B |
512+64 |
0.3 |
xx |
🔧 Advanced Features#
Custom Hash Weights#
# Use pre-trained hash weights
config.set_hash_weight(custom_hash_weights)
Hardware Optimization#
CUDA: Optimized kernels with bit-packing, hamming score, and top-k selection
NPU: Native
npu_sign_bits_packoperations, optimized fused kernels for hamming_dist_top_k and kv_select.CPU: SIMD-optimized implementations
🎓 Citation#
If you use GSA in your research, please cite our ACL 2025 paper:
@inproceedings{kvcomp2025,
title={HATA: Trainable and Hardware-Efficient Hash-Aware Top-k Attention for Scalable Large Model Inference},
author={[Ping Gong, Jiawei Yi, Shengnan Wang, Juncheng Zhang, Zewen Jin, Ouxiang Zhou, Ruibo Liu, Guanbin Xu, Youhui Bai, Bowen Ye, Kun Yuan, Tong Yang, Gong Zhang, Renhai Chen, Feng Wu, Cheng Li]},
booktitle={Proceedings of ACL 2025},
year={2025}
}
🤝 Contributing#
We welcome contributions! Please see the How to contribute section of Developer Guide for details.
🌟 Star UCM repository if you find GSA useful!